Data Center Technologien
Die Technologie der Hyperscaler im eigenen RZ. Unsere Data-Center-Tech-Lösungen bilden die Basis für Ihre Infrastruktur. Wir unterstützen Sie bei der Planung und Umsetzung Ihrer Rechenzentrumslösung, von der Konzeption bis hin zur Implementierung. Unsere Experten sind spezialisiert auf Datencenter-Infrastruktur-Management (DCIM), Netzwerke und Automatisierung.
Planungen
Moderne Infrastrukturen funktionieren anders, als sie vor 20 Jahren gebaut wurden: Von Leistungsdichten mit mehr als 30 kW pro Rack über 100G, 200G und 400G-Verbindungen bis hin zum digitalen Zwilling in Netbox - doch dafür muss auch das Rechenzentrum entsprechend geplant werden. Wir unterstützen Sie bei der Planung und Konzeption Ihres Rechenzentrums, dass auch den kritischen Anforderungen des Energieeffizienzgesetzes stand hält:
- Hochdichte und wassergekühlte Systeme
- Passive Verkabelung und Interconnects
- Notwendige Komponenten für ein modernes RZ
Und dort, wo unsere Expertise aufhört, haben wir die richtigen Fachplaner an der Hand - von TGA über Elektro bis hin zur Klimatechnik. Aus diesem Grunde engagieren wir uns auch beim Verband innovatives Rechenzentrum (VIRZ ).


Datacenter Infrastructure Management
- Größere Kontrolle über Ihre Infrastruktur.
- Mehr Sicherheit durch bessere Übersicht.
- Eine bessere Entscheidungsgrundlage und somit Kosteneinsparungen.
All das bietet Ihnen ein DCIM. Netbox ist das webbasierte Tool für zentralisiertes Infrastrukturmanagement und IP-Adressverwaltung. Als einzige Quelle der Wahrheit im Rechenzentrum bietet es eine umfassende Dokumentation von Servern, Netzwerken und Geräten. Aber mehr noch: Es ist die Basis für die Automatisierung unserer Servercluster und Netzwerke und ermöglicht eine effiziente und sichere Verwaltung Ihrer Datencenter-Infrastruktur.
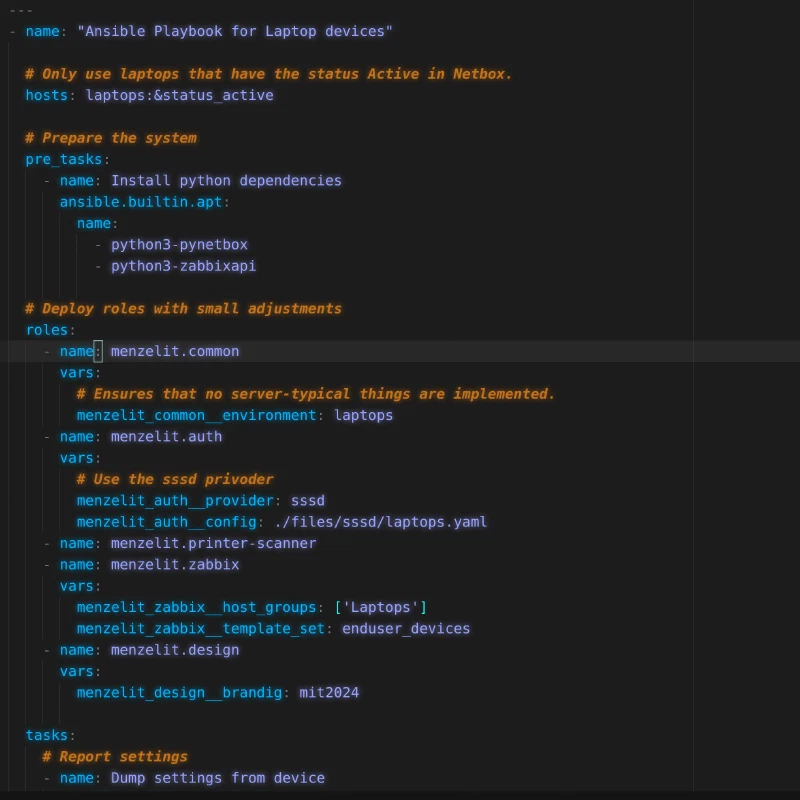
Automatisierung
From pet to cattle - vom Haustier, das man hegt und pflegt, zum Rindvieh, das geschützt und verlässlich genährt wird, bringt Automatisierung ähnliche Vorteile in den Datenzentrumsumgebungen. Durch automatisiertes Server-Management können Fehler schnell identifiziert und behoben werden, was höhere Uptime-Rate und Sicherheit ergibt. Außerdem reduziert sich die Arbeitsbelastung für IT-Experten und ermöglichen es ihnen, sich auf strategische Aufgaben zu konzentrieren. Wir unterstützen bei…
- … Server- und Netzwerkautomatisierung mit Ansible
- … Cloud-Automatisierung mit openTOFU.
- … Anbindung der Automatisierung an ein DCIM und IPAM.

Green IT
Unser Engagement für eine nachhaltige Zukunft begann vor über 10 Jahren, als wir erstmalig hocheffizienten Systemen und Wasserkühlung für die HPC-Cluster unserer Kunden einsetzten. Heute ist dies für HPC-, aber auch AI-Cluster selbstverständlich. Durch diese Maßnahmen reduzieren wir den Energieverbrauch und den CO2-Fußabdruck Ihrer Anlagen. Unsere Strategie: Eine nachhaltige Infrastruktur für eine bessere Zukunft. Wir unterstützen Sie bei…
- …der Konzeption hochdichter und damit hocheffizienter Systeme
- …der Planung rund um Wasserkühlung.
Netzwerke
Wir bauen hochleistungtaugliche Netzwerke als Basis für Private-Cloud, HPC und Machine-Learning-Cluster. Auf Ethernet und Infiniband setzen wir unsere Standards, um maximale Leistung und Effizienz sicherzustellen. Unsere Expertise reicht von komptakten 2-Switch-MLAGs mit VLAN bis zu komplexen Spine-Leaf-Architekturen mit knapp 100 Switches auf 400 Gbit-Basis und VXLAN. Und egal wie groß: Unsere Netzwerke sind optimiert für die Anforderungen von High-Performance-Anwendungen.
- Auf Wunsch vollständig automatisiert , etwa auf Basis von Ansible und Netbox .
- Geeignet für Multi-Brandabschnitt-Szenarien und OT-Anforderungen.
- Geeignet für Overlay-Netzwerke im Private-Cloud-Umfeld.


Storage
Für unsere HPC-, ML- und Private-Cloud-Cluster bauen wir maßgeschneiderte Storage-Lösungen auf. Wir setzen dabei nicht auf eine einzige technologische one size fits all Lösung, sondern passen das Storage-System individuell an die spezifischen Anforderungen des Szenarios an.
- Für HPC- und AI-Anwendungen kommen regelmäßig HPC-Storages wie Lustre oder BeeGFS zum Einsatz.
- Für Private-Cloud-Lösungen setzen wir auf besonders resiliente und redundante Storage-Systeme wie Ceph oder GlusterFS.
- Natürlich wird dieser Storage auf Wunsch auch vollautomatisiert und gemonitort.
Monitoring und Logging
Was nicht gemonitort wird, darf kaputt gehen. So lautet eine bekannte IT-Weisheit. Wir verstehen die Bedeutung einer umfassenden Überwachung Ihrer Data-Center-Aktivitäten. Unsere Experten setzen moderne Monitoring-Lösungen ein, wie etwa Zabbix oder Prometheus mit Grafana, um Ihre Datencenter-Komponenten ständig im Auge zu behalten. Mit real-time Dashboards und Alert-Funktionen können Sie schnell auf Probleme reagieren und die Verfügbarkeit Ihrer Servercluster steigern.
- Nahe alle Komponenten in Ihrem Rechenzentrum sind überwachbar - von der Servern über das Netzwerk bis zur Kühlung.
- Auf Wunsch binden wir Ihr Monitoring im Zuge eines Wartungsvertrags an unser zentrales Monitoring an und überwachen Ihre Systeme 24/7.
- Moderne Alerting-Möglichkeiten gehen weit über Mail und SMS hinaus.


24/7-Support & SLAs
Techniker wissen, dass Monitoring und Logging für die Uptime wenig helfen, wenn beim Ausfall einer Komponente niemand da ist, der reagiert. Deshalb bieten wir Service-Level-Agreements (SLA) an, die flexible Reaktionszeiten ermöglichen, wie zum Beispiel 24/7-Betreuung. Unsere SLA sind darauf ausgerichtet, Ihre Bedürfnisse zu erfüllen und sicherzustellen, dass Ihre Systeme immer verfügbar sind, wenn Sie sie benötigen.
- 24 Stunden am Tag, 7 Tage die Woche, 365 Tage pro Jahr.
- Aufschaltung auf unser zentrales Monitoring mit Alerting für die Mitarbeiter.
- vereinbarte Reaktionszeiten enthalten immer eine Ersteinschätzung durch qualifizierten Techniker - kein Callcenter!
Schreiben Sie uns
Egal, ob technische Frage, Feedback oder Angebotsanfrage, Sie können uns jederzeit eine Frage via Kontaktformular oder via Mail an post@menzel-it.net senden.
Telefonisch sind wir werktags von 09:00 - 16:30 Uhr erreichbar. In dringenden Notfällen können Sie uns allerdings auch 24/7 erreichen - rufen Sie dazu gerne unter +49 30 5130 444 - 44+49 30 5130 444 - 44 an.